What do The Perfect Score movie (2004), LLMs passing the bar exam, and a trained YOLO model correctly detecting objects have in common? These are all examples where the AI models, or students, achieve seemingly great results not because of the model generalization, but due to data leakage – whether it’s because the students stole the example questions the night before, or that the models are literally trained and evaluated on the same or very similar data.
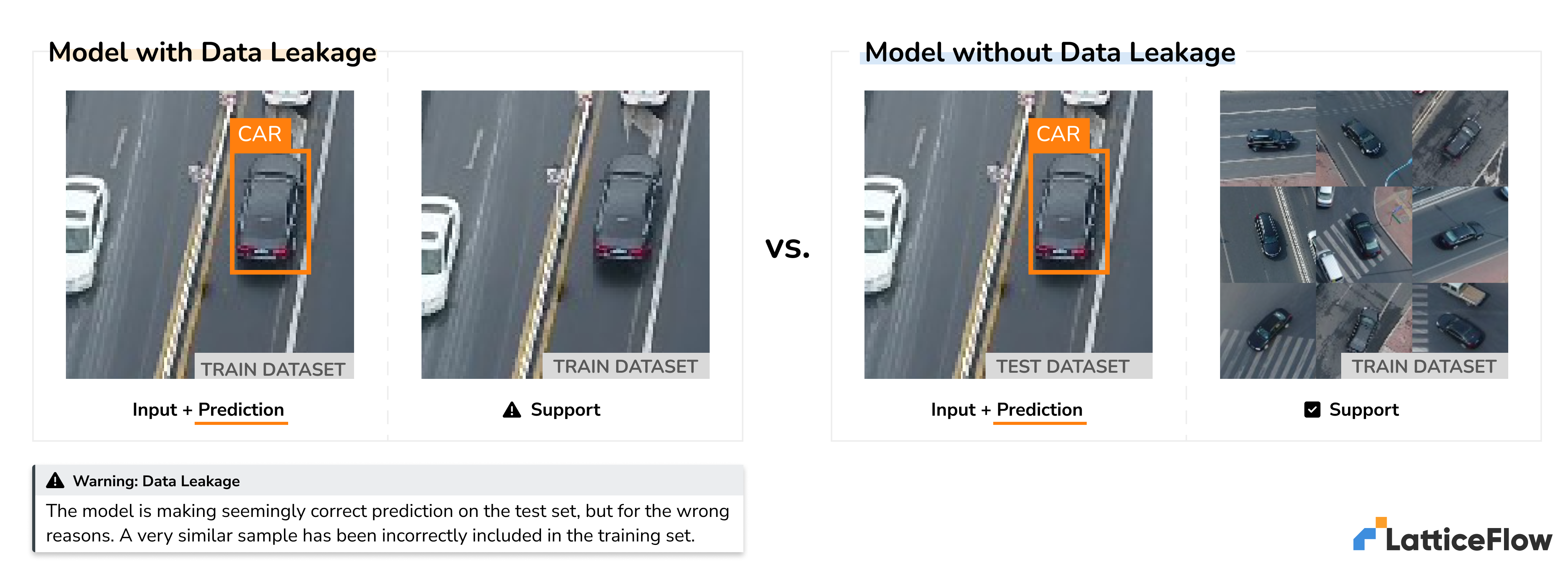
Unsurprisingly, data leakage is not new and has been pointed out on numerous occasions over the years. As Francis Chollet, the creator of Keras, put it recently: “LLMs struggle with generalization (the only thing that actually matters) due to being entirely reliant on memorization … Benchmark-topping LLMs are trained on the test set …”.
What is surprising though is: how is it then possible that such a widespread issue affecting virtually all types of machine learning models has not yet been addressed?
Is it because the risk is low? Quite the opposite – data leakage can lead to gross overestimation of model performance, often discovered only after the model has been deployed, leading to significant development and reputation costs. As an example, in the latest work published at CVPR by Paplham and Franc [1], data leakage and other factors related to the experimental setup were found to result in up to 50% performance degradation. A similar study across optical coherence tomography (OCT) applications revealed inflated accuracy from 5% to 30% [6]. To put this into perspective, unless you are willing to risk that the continuous performance improvements of your specialized methods are in fact negligible, then the risk is not acceptable.
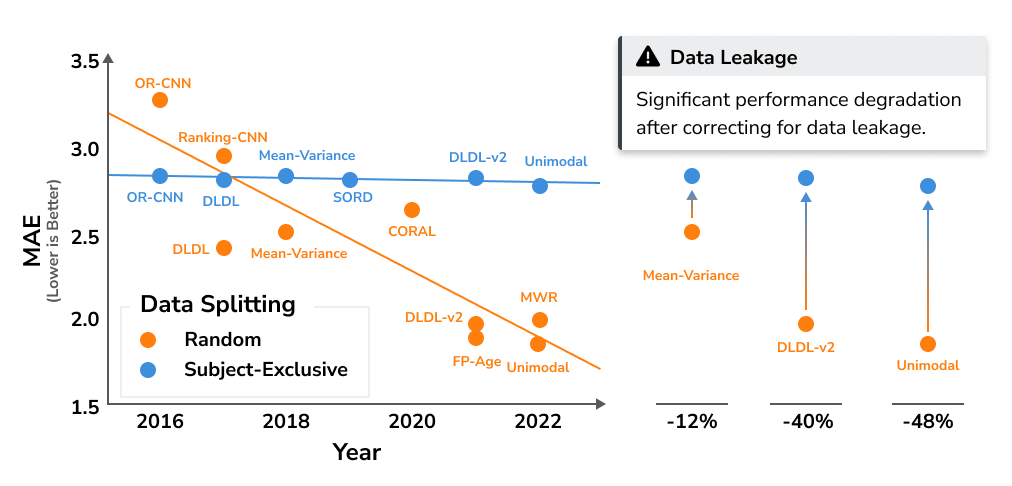
If it is not the risk, then what is it? It turns out that one of the main challenges is how to reliably find data leakage in the first place.
- checking for overfitting is one approach, but that has two caveats – i) overfitting is just a symptom, not the root cause, and ii) it is possible to have data leakage without overfitting.
- spoting suspicious results is probably the most common approach. Unfortunately, this is a generic advice that not only requires domain experts, but is also not possible to operationalize and error prone (i.e., how to even define a “suspicious result” and how would one get confidence that there are none?).
In what follows, we will learn:
- What are the most common root causes of data leakage?
- What are the automated checks that can be used to detect data leakage?
Root Causes of Data Leakage
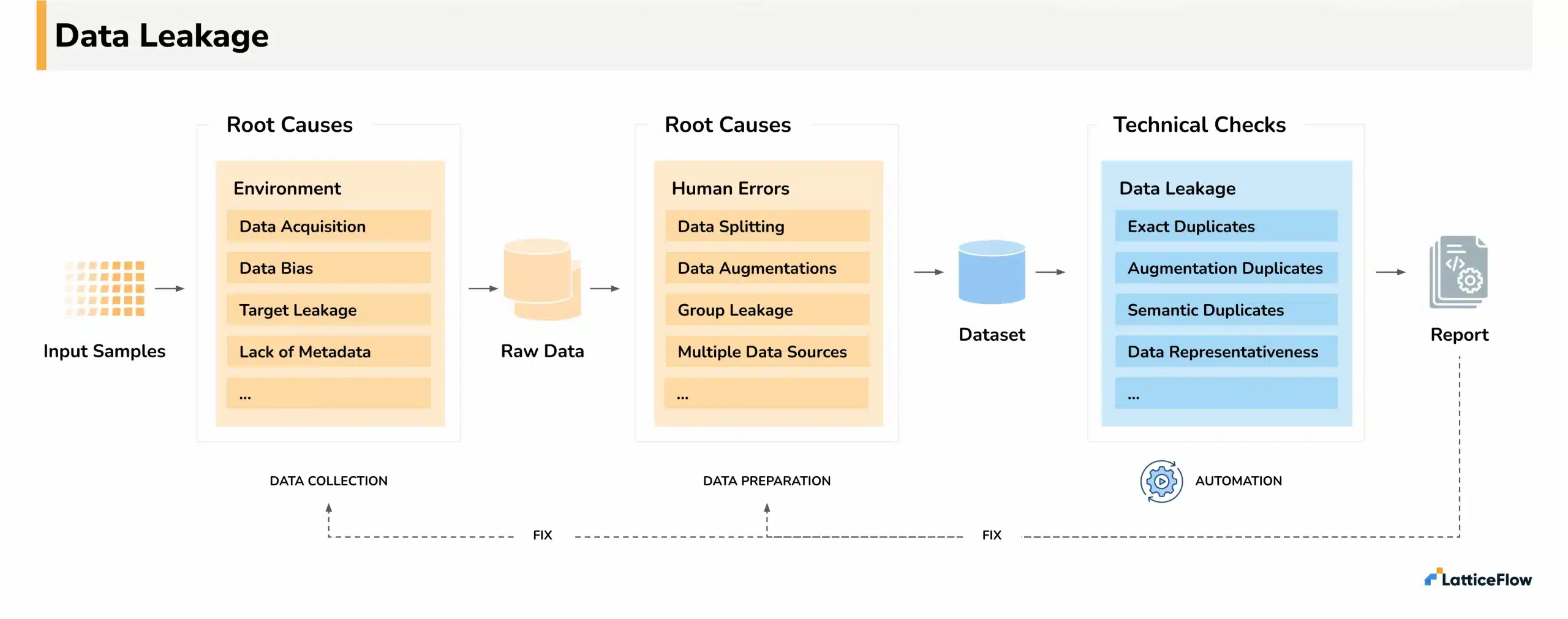
The first step in avoiding data leakage in our models is understanding its root cause. We divide data leakage root causes into two categories:
- due to external factors during data collection, such as the way the data is acquired or that the data is aggregated from multiple sources with unknown conversions, or
- due to implementation errors in the data preparation phase, such as incorrect separation of training and test split or incorrect data augmentations.
As the name suggests, external factors are an inherent part of data collection and should always be addressed as part of the data curation process. On the other hand, human errors are examples of data leakage that are purely because of implementation errors when preparing the data for training and testing. The good news? As we will see, both of these can be addressed using suitable technical checks.
External Factors
Data Acquisition Depending on the task, there can be inherent potential for data leakage due to how the data is acquired. For example, when working with video datasets, consecutive frames are typically very correlated and similar, if not equal to each other.
Similarly, even if the frames are not consecutive, they can include the same area or content. For example, if there is a camera mounted on a train to detect defects on the rails, one needs to be careful that different runs of the train that cover the same geographical area are not assigned to dataset splits at random. Instead, the same location should be fully assigned to either the training set or the test set.

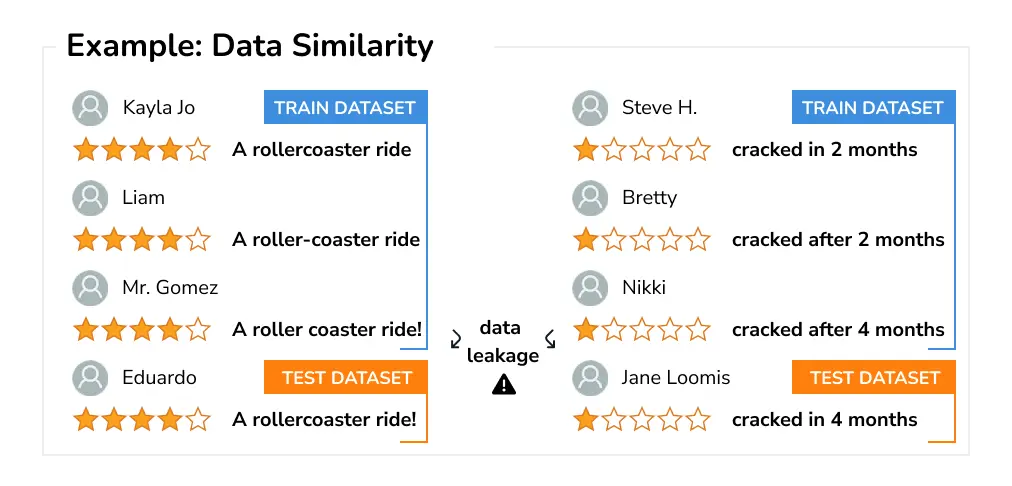
Data Similarity Another root cause for data leakage is data similarity. This happens when the individual samples are very similar to each other either because of the way they were acquired (e.g., repetitive content obtained from users or using a mounted camera with a fixed view) or due to custom pre-processing, such as splitting high-resolution images into smaller patches.
For example, when training sentiment analysis models from natural language, one common source of data are product reviews. Such reviews however naturally contain a lot of repetition or paraphrasing as many users might write similar reviews. If not careful, such similar reviews can easily end up in different splits leading to biased evaluation metrics.
As another example, in order to detect small defects, a common practice is to split high-resolution images into smaller patches that are fed to the model. However, for use cases where the input is highly repetitive/similar, such as detecting defects in manufacturing, this can easily lead to data leakage.

Target Leakage Target leakage happens when the target to be predicted has been inadvertently leaked to the dataset. This can happen if the data has not been sanitized thoroughly before training, such as not removing an attribute containing information not available at inference time. For example, a dataset for predicting whether the user would leave or stay on a retail website should not include “session length”. Naturally, this attribute is very predictive of the task, but unfortunately only available after the user has decided to leave the website.
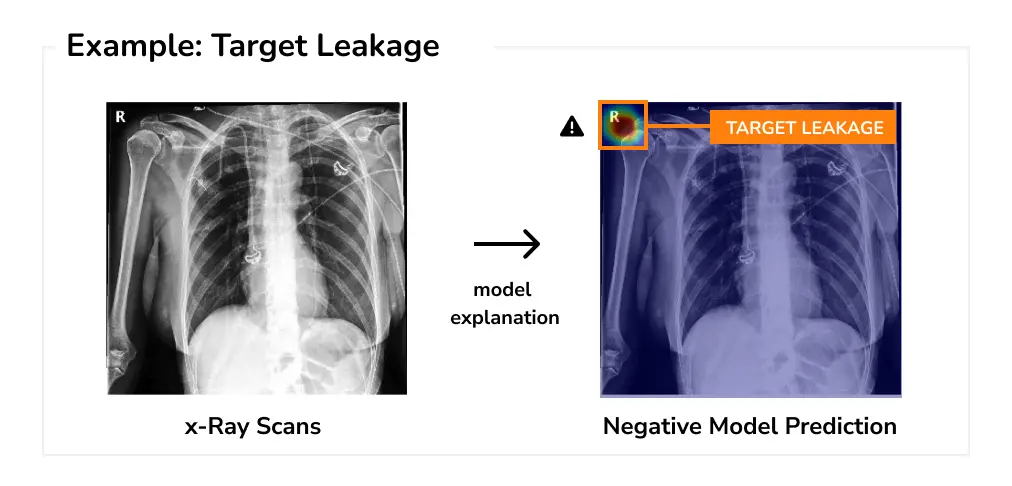
More importantly, target leakage can also occur due to strong data bias or spurious correlations, which the model can exploit to learn shortcuts. For example, a medical model trained to identify COVID-19 positive cases from x-ray images has wrongly learned to use the “R” marker in the image as a signal to predict COVID-19 negative outcomes. This is because of target leakage in the COVIDx dataset, which was created by combining crowdsource COVID-19 positive samples and negative samples from Pediatric pneumonia dataset. However, because of data bias, the negative classes in the pneumonia dataset had the markers, which were picked by the model.
As another example, in order to detect small defects, a common practice is to split high-resolution images into smaller patches that are fed to the model. However, for use cases where the input is highly repetitive/similar, such as detecting defects in manufacturing, this can easily lead to data leakage.
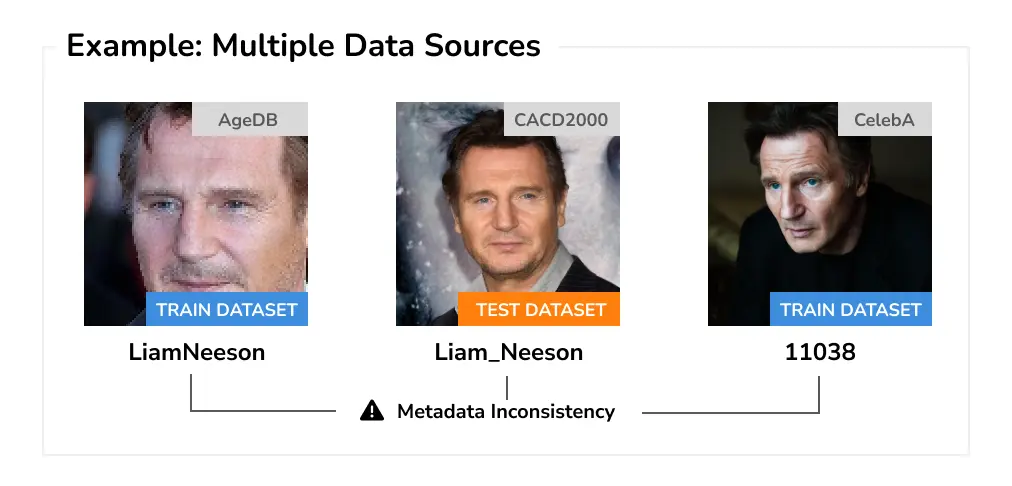
Multiple Data Sources Working with multiple data sources is an inherently hard problem due to differences in annotation formats, labeling taxonomies, potentially unknown pre-processing steps applied to the data, missing metadata such as when and where the sample was acquired, or simply redundancy in the combined dataset.
As an example, consider the task of identity verification or age estimation. Here, data leakage can easily occur if the same person is inadvertently included in both training and test sets. Correctly accounting for this can be however difficult as the metadata about the person can be missing, ambiguous, or have a slightly different format (e.g., no middle name).
Implementation Errors
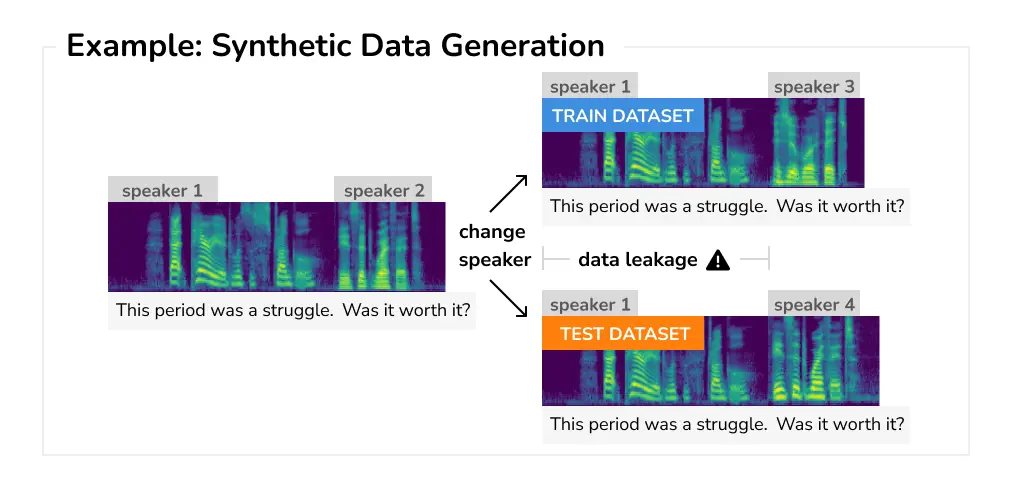
Synthetic Data Generation Unless you are training models for use cases with a constant stream of unlabelled data, you probably already used some form of synthetic data generation to diversify your dataset and improve the model generalization. Unfortunately, synthetic data generation also comes with several caveats that can result in data leakage. In particular, it is easy to generate the same object or background in multiple samples, which might then end up in different dataset splits.
Furthermore, a common issue is leaking only part of the sample. As an example, let us consider an automatic speech recognition model that, given an audio input, generates the corresponding transcribed text. One way to augment the dataset is to select an individual speaker and synthetically replace the acoustic features to correspond to a different speaker while keeping the same linguistic content. Unfortunately, if such samples are used for both training and testing, it also means the unaltered content is leaked.
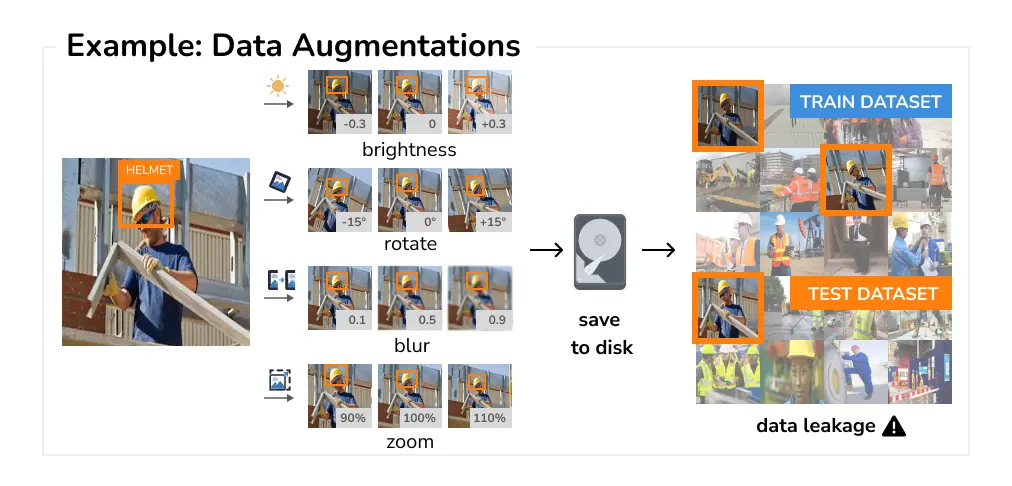
Data Augmentations Data augmentations are a core component of effectively training all modern deep learning models. In fact, data augmentation is even suggested as one way to address data leakage. Unfortunately, while this advice might sound reasonable at first, not only does it not remove the data leakage, it can introduce additional data leakage if augmented versions of a single sample are assigned to different dataset splits.
In general, there is no risk of data leakage when the data augmentations are applied on the fly as part of the training loop. However, data leakage can happen when the data augmentations are expensive to apply and are pre-computed and serialized to disk before the training. In this case, the subsequent splitting needs to take into account the information of how each augmentation was generated, in order to prevent inadvertently leaking the data.
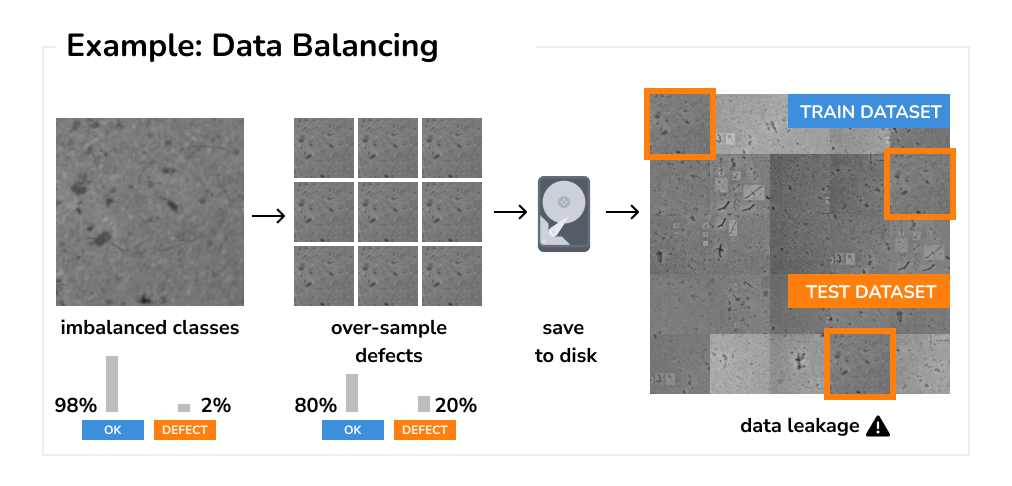
Data Balancing When working with imbalanced datasets, a common technique is to over-sample the minority class, to balance the overall class distribution. Whether the oversampling is done at random, by introducing noise, or by using advanced techniques such as synthetic data generation (e.g., SMOTE [4]), all these techniques can lead to data leakage if implemented incorrectly.
As an example, consider the common practice of oversampling the minority class as part of dataset preprocessing. In this case, synthetic variations of underrepresented samples are generated in a separate step and then saved to disk as a new dataset. However, as soon as this new dataset is used and partitioned into training and test splits without the knowledge of how it was generated, new data leakage immediately occurs.
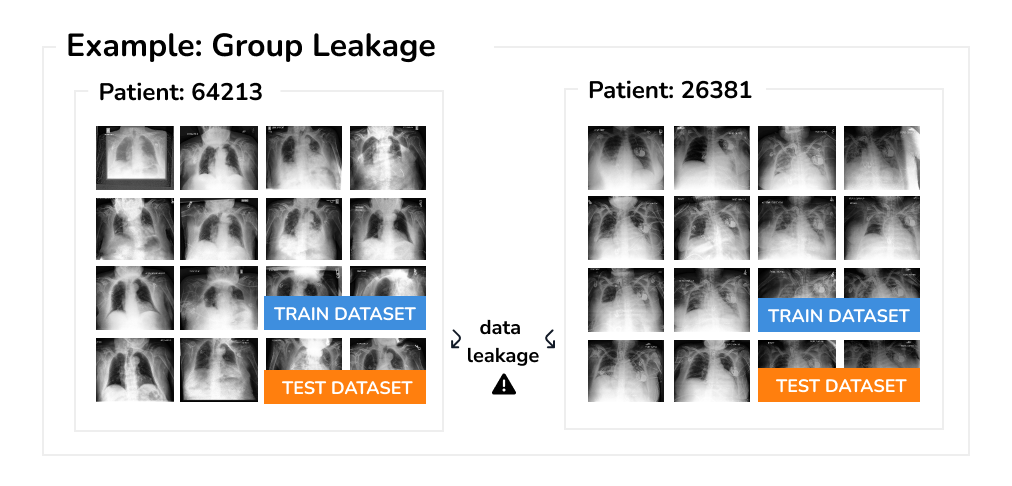
Group Leakage Another case when data can inadvertently leak and affect the evaluation is when the dataset contains multiple samples associated with the same person or group. Imagine having multiple X-ray scans taken from a single patient, yet some are used in training and others for evaluation. Clearly, for such leaked samples the model can easily pick up other “spurious” features such as the body shape or low-level textures, rather than the actual features of pathology.
This is exactly what inadvertently happened in the CheXNet work performed by Stanford researchers, including Andrew Ng [3]. In the original dataset version, the dataset was split without taking into consideration that a single patient can have multiple scans. In fact, out of 112 120 scans, only 17 503 scans (15%) are from patients that contain only a single scan. Note, this error has been pointed out and promptly corrected by the authors in the revised version of the paper.
The key challenge for resolving group leakage are datasets where the group information is not available, incomplete, or even incorrect. This can easily happen when datasets from multiple sources are combined together. In this case, we need to first recover the group metadata, before correct separation can be made.
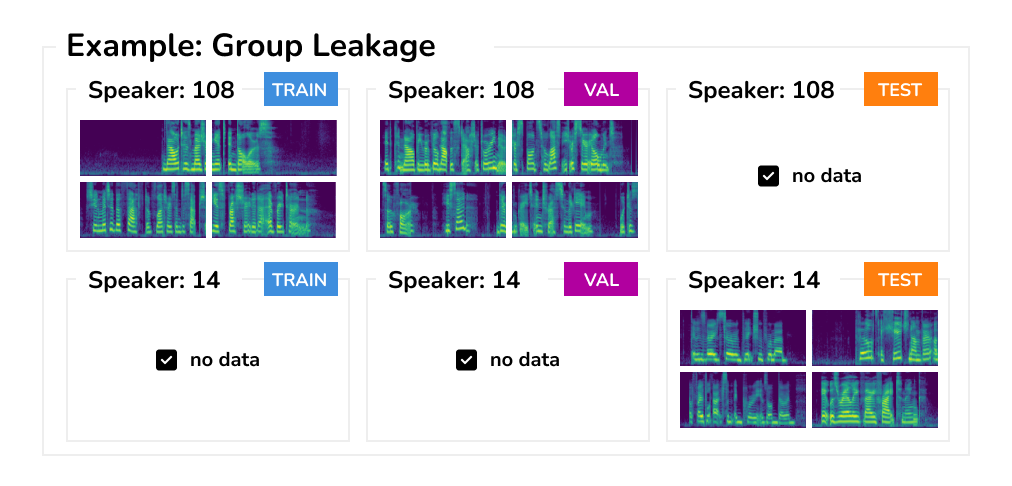
Temporal Leakage The importance of data splitting that correctly accounts for the temporal aspect is a must-have for any time series forecasting model. Otherwise, we are training the model on future periods and evaluating on the past, instead of doing the opposite. A common practice to avoid data leakage, as well as make use of the maximum amount of data, is to use the rolling forecasting technique that moves the training and test sets in time [2].
However, the issue of using temporal data arises also in other domains such as computer vision, natural language or speech. For example, when predicting objects in video, care needs to be taken that the video is split into frames without leaking future information into the past. Note, contradictory to the common belief, this happens regardless of how the splits are ordered within each video.

Technical Checks for Detecting Data Leakage
Having seen a diverse set of root causes for data leakage, the key question is how to avoid it in practice. More importantly, we are interested in a set of technical checks that can be included as part of the standard engineering practice, rather than the current practice of depending on expert machine learning engineers spotting issues by chance. Based on the root causes, we define four types of data leakage checks for similarity, group, target, and temporal data leakage.

Preventing Similarity Data Leakage
The intuition behind preventing data leakage due to similar samples is quite straightforward – detect all similar samples and check whether they belong to the same split. The challenging part in practice is twofold: i) how to define a suitable distance metric to measure sample similarity, and ii) how to implement this check in a scalable way when working with large datasets.
Exact duplicates
The simplest type of similarity metric is equality, that is, two samples that are equal in all attributes. For computer vision, this corresponds to checking the equality of every pixel, for natural language every character, or the equality of every record for structure datasets. Over the years, many algorithms have been developed to answer this question efficiently, often focusing on the broader task of information retrieval, such as Locality Sensitive Hashing (LSH) [5].
Augmentation duplicates
Going beyond exact duplicates, finding data leakage introduced by incorrect data augmentations or data balancing requires extending the similarity metric to include common data augmentations. For computer vision, this can include rotations, flipping, color jitter or adding noise. For natural language, common augmentations include adding typos, using synonyms, paraphrasing, or noisy word addition or removal. Similarly, for speech processing, augmentations include shifting the pitch, time stretching, adding or removing silence and noise, and more. As can be seen, even for common data augmentations there is already a huge variety that only increases when considering multiple modalities. For example, if in computer vision one can at least take advantage of the fact that the input size is fixed, this is not the case for natural language or speech. Here, the input size is dynamic and any similarity metric needs to support dynamic matching in order to avoid false negatives. Commonly, similarity metrics that capture data augmentations are based on perceptual hash algorithms, which, contrary to cryptographic hash algorithms, produce equal outputs for minor input variations.
Semantic duplicates
Finally, semantic duplicates include any modifications of the input sample that can not be captured by data augmentations, yet result in high perceptual similarity. For example, this can include adding and removing objects for computer vision, adding watermarks, overlaid text, slight perspective changes and many more. These are naturally very hard to capture and instead of trying to design custom heuristics, state-of-the-art techniques are based on dedicated deep learning models trained on this task.
Preventing Group Data Leakage
For group data leakage, as long as the group information is available, the technical check boils down to ensuring that all samples within the same group are fully contained within a single split. The main challenge in implementing this check in practice is missing, incomplete or even incorrect group information. Depending on which case we are in, different techniques can be used to recover the group information. For example, if the group information is incorrect, we can take advantage of techniques for finding wrong labels to automatically highlight inconsistent group metadata. On the other hand, if the group information is missing or only partial, we can take advantage of techniques used for hypothesis testing to generalize the partial group to unseen samples.
Preventing Temporal Data Leakage
Similar to group data leakage, the main challenge in implementing temporal data leakage check are cases where the temporal data can’t be trusted or is incomplete. In this case, similarity data leakage can be used to flag samples that are too similar to each other, even if the temporal metadata is not available. Afterward, rolling forecasting techniques that move the training and test sets in time are then typically used to take advantage of the full dataset, without leaking any future information into the training [2].
Preventing Target Data Leakage
Automating target data leakage is conceptually the most challenging as it requires distinguishing between spurious features that should be removed and valid features that should be kept. For this reason, this check does require human interpretation and the automation comes from searching for suspicious features. To achieve this, it is useful to combine existing feature attribution methods and general per-sample explanation, together with clustering techniques to cluster similar explanations together. Afterwards, the domain expert can explore the clusters with similar explanations in bulk, rather than analyzing one sample at a time.
References:
- [1] A Call to Reflect on Evaluation Practices for Age Estimation: Comparative Analysis of the State-of-the-Art and a Unified Benchmark. Jakub Paplham, Vojtech Franc. CVPR’24 [to appear].
- [2] Hyndman, R. J., & Athanasopoulos, G. (2018). Forecasting: Principles and Practice. (2nd ed.) OTexts. https://otexts.org/fpp2/.
- [3] Pranav Rajpurkar, et. al.. CheXNet: Radiologist-Level Pneumonia Detection on Chest X-Rays with Deep Learning. 2017.
- [4] Chawla, Nitesh V, Bowyer, Kevin W, Hall, Lawrence O and Kegelmeyer, W Philip. “SMOTE: synthetic minority over-sampling technique.” Journal of artificial intelligence research 16 (2002): 321–357.
- [5] Aristides Gionis, Piotr Indyk, and Rajeev Motwani. 1999. Similarity Search in High Dimensions via Hashing. In Proceedings of the 25th International Conference on Very Large Data Bases (VLDB ’99). Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 518–529.
- [6] Tampu, I.E., Eklund, A. & Haj-Hosseini, N. Inflation of test accuracy due to data leakage in deep learning-based classification of OCT images. Sci Data 9, 580 (2022). https://doi.org/10.1038/s41597-022-01618-6


